posted under category: General on October 30, 2021 by Nathan
A blog series in which I confess to accidentally having written my own poor version of a solved problem
It was my first .NET Core project ever. I knew a little ADO and ADO.NET from many years before, and I quickly learned enough about the built-in ORM, Entity Framework Core, to know there isn't a way to map SQL Server's stored procedures to EFCore entities. It's a shame.
This project had a team of data scientists writing a bunch of SQL that came out as record sets from stored procedures. Data scientists aren't necessarily great at SQL, but they managed to get it done. Questioning their methods wasn't something that was in the cards for me. Believe me, I tried. Nevertheless, they produced data, and I needed to consume it.
So the problem remained: there is no simple way in .NET Core to pull rows of data from a stored procedure into the application. So I started exploring. I have a pretty good memory, and I remembered the names of some classes in the System.Data namespace which, to my surprise, were still there. This is the fully rebuilt .NET Core and ADO.NET Core, but a bunch of the old things I knew from over a decade ago were still in there. Astonishing!
Thanks to google and stackoverflow, I managed to piece together something that queried the database. Moving forward, I could eventually read results! This was really working. I got a single stored procedure mapped to a simple class I built. Commit. Push. Deploy. Happy.
Mission accomplished, right? Hardly.
At this point, I was like 300 lines of code into something that I used to be able to do in 10. There were two problems:
-
Building and sending the query takes multiple calls to awkward ADO APIs, and it's just too many lines of code. Sure maybe there's no better way to do it, and I appreciate all the control I get, but I'm just trying to make a little web app here. Why can't they just open and close the connections for me?
-
Getting the data back is completely manual. I have to manually loop over the iterator that's streaming all the records from the server, set the columns by their ordinal position, and then cast types into my record object. This is a lot of lines of code.
In summary of my two problems, it's (1) the input, and (2) the output. Hah! Yeah literally the whole thing basically. sigh
So it was an obvious thing to quickly evolve it. I should be able to remove a lot of the boilerplate junk by adding some convenience features. All of a sudden, I could call the procedure in a single line of code! I added my connection to the dependency injection system so that any object in the data access layer can request it.
With a serotonin high off that success, I started to tackle the data retrieval problem. I poked around enough until I found how to get the return columns by their column name instead of their ordinal position in the recordset. But how do I know how the columns in the query compare to the properties in my data record class? The only way without a bunch of configuration is to use Reflection. I modified it to read the columns in the recordset and search through the properties in the target class to match it up. Works perfectly!
Now the API is something like this:
List<MyDataRow> data = await dataService.QueryAsync<MyDataRow>("exec usp_GetData");
Getting fancier, sometimes our front-end application needs different names for columns in the database. Also our data science team sometimes uses illegal names like columns with spaces and whatnot, so that's a mess. I looked around and found that ADO.NET Core has column alias hints you can give to properties for EFCore entities, why not use them here?. Adding those means my data-to-record mapper needs to build a dictionary between the incoming column names and the outgoing properties, with the possibility of multiple aliases or just with the property name. I suppose that's simple enough.
Then there's the problem of input parameters. Of course we need the ability to pass in parameters. ADO has this covered typically, with a SqlCommand class. Naturally, I wanted to have a way to simplify even that, but that one looks like it's nearly as simple as possible, so very little work to do here. It's actually inconvenient to create a SqlCommand, so I made a convenience method on my DataService from a fake SqlConnection and connect it to the actual one once the request was made.
Now queries looked like this:
var cmd = dataService.CreateCommand();
cmd.CommandText = "exec usp_GetData @myParam";
cmd.Parameters.Add("@myParam", value)
var data = await dataService.QueryAsync<MyDataRow>(command);
Is it the simplest I could make it, and it felt pretty good, so that's all I need to go to production! (I'm kidding! [kinda]). All the rest of the database connection opening and closing, data-model binding, and anything else is all handled by this DataService of mine. It could take any query data, populate any matching data record class, and spit out a List<T>. And it could do it really, really fast!
But I promised this was a duct-tape-and-shoestrings thing, didn't I?
Yes, in line with the rest of my accidental frameworks that have already been invented, I had two final problems - the first, as always, being portability. Taking this tool to a second app actually worked really well, which is surprising. Well, that is, until they needed me to connect to an Oracle server, and a Teradata server. I realized quickly that the SqlConnection is really just for SQL Server.
Taking it to a second app of course is where it goes from part of a product to a product of its own. Now instead of Sql*, it's Db* classes, like DbCommand and DbConnection, but configuring it to work with the differences in data types between servers ended in some unfortunate compromises. I'm sure that would have gotten ironed out eventually, but before long I was off to another project.
The second way that my framework fell short was in data mapping. There was always a single line of code that was prone to break, right where database types were mapped and cast into C# data types. The Flux Capacitor that did it was a single line of code that I commented very well. There are just some fields that don't map correctly, and every time I ran into a new one, or tried to cast it to the wrong type, I would get runtime errors. I think the answer to this would have been a utility called Automapper, but by now, why even?
What did I learn?
This was genuinely a fun project. In addition to the underlying ADO roots still inside the framework, I also got to really play with the implementation side of generics for the first time. Plus the chance to make my own ORM is just something that seems like fun to me. I'm still surprised that something like this isn't just included directly into the framework. Why is EFCore so limited?
I'd seen mention of the Dapper framework, and AutoMapper, a few times on stackoverflow answers, but didn't investigate them any further. I should really follow up on those kinds of leads more often. While it sounds like there is a problem with me -- and very likely there is in this case -- there is also the fact that my company doesn't like external software. If we didn't write it, how can we trust it? More than just a not-invented-here mentality, external software always has to go through a waiver process, and even new versions always have to be re-verified. It's often more trouble than just playing with some code and writing something custom.
Dapper
On the next project, I finally followed the stackoverflow advice and looked into Dapper, which was initially written for StackOverflow.com. Surprisingly, it wasn't much different than my little framework, with similarly named methods. Plus, as usual, switching to Dapper would mean that I don't have to write my own unit tests for it. Dapper was surprisingly easy to plug in, and thanks to its use of extension methods and anonymous types, it solves a lot of the usability problems I created for myself.
I do wish Dapper had better support for cancellation tokens, especially since I know it's built into the .NET Core framework's data access methods, and is relatively easy to pass an aborted HTTP call through in order to cancel a data call.
I also struggle a little with the fact that I can't write unit tests on code that uses Dapper to talk to my database because extension methods can't be overridden. Oh well, I guess. That's the price we pay for some things.
Overall, I'm much happier using Dapper for raw data access.
posted under category: General on October 21, 2021 by Nathan
A blog series in which I confess to accidentally having written my own poor version of a solved problem
I was new to the “new” JavaScript. You know, the one we started doing when Node.js went mainstream and everybody started using NPM to launch their apps, and back when leftPad was cool. It’s fair for me to be this cranky about it; I wrote my first line of JavaScript in 1997, and I jumped in with both feet through the Prototype years, the jQuery years, and now, something new: NPM Packages and Webpack.
The JavaScript language was evolving, too. Meanwhile I was still trying to support my Internet Explorer users. That’s the corporate life. So the new ecosystem, plus the new language features, plus the new libraries, all had my head in a spin for literally years. Ours is a learning career. When you stop learning, you might as well stop your career. So, I guess the state of confusion is a good place to be.
My first Vue.js project started off on the far side of the progressive framework’s spectrum. That is, I added a tag to my layout and wrote a new Vue for each page. Vue.js is great at easing you into this world.
My next step was to normalize the way we bring data into the UI. We needed to use a token security system, and the other developers were already trying to get their own JWT and figure out how to copy & paste that code to all the features they were working on. I needed to act fast so that this didn’t get out of hand.
A cursory glance across the JavaScript universe brought up a few contenders - Axios, the download leader, whatwg-fetch and isomorphic-fetch that gave me trouble (probably beccause IE wasn’t compatible), and there were a few others that just didn’t pan out. Then I thought about the trouble of adding yet another .js file to my application, the additional download size, and what we really needed for this project. Then, you guessed it, I decided to just do it myself. How hard could it be?
It turns out, not very!
The first version of this first Vue project had jQuery built in, and we weren’t to the point of ditching jQuery yet, so since it was available, I could utilize it to hide my XMLHttpRequest business. I was confident that I could replace jQuery later in this instance.
In front of jQuery’s $.ajax method, my http “class” had get/put/post/delete functions as its API - finally a central place for all the API requests to come in. We added some UI logging on it to track API timing. We added JWT management so that it would all be handled inside the black box. It was also the smart place to add global error handling. This worked. I changed all the API code throughout the application to use my method, and we went forward successfully.
By the end of my time on that project, I had figured out how to get Webpack to precompile our Vue applications - individual applications per page on the site. I bought that knowledge forward to my next project. Again, everything seemed to be copy-and-pasted so I centralized the code and used the browser-native Fetch api with Babel targeting IE11 for compatibility and to automatically load any polyfills for me since IE doesn’t have Fetch at all.
This next iteration was even more successful. I could finally use ESM from the start, so I exported my 4 verbs - get/put/post/delete - which called into an internal function to contact the server and return the data. It didn’t take long until I found the cracks in that system.
Fetch is more than happy to return server-side errors to the UI. I was going to handle it. I wrote a bit of code before realizing that this is probably something that Axios already does. I double-checked the package size; for some reason I thought Axios was going to add like 40kb to my vendor bundle. It turns out it’s only 16kb. Not bad. Plus Axios is well tested, and I don’t want to write all the unit tests. It was time.
I switched to letting Axios handle the connections instead of Fetch. I still have my own adapter over it - not necessarily to simplify things, but more to control and standardize everything.
What did I learn?
Well, I’d like to say I learned to not sweat over a 16kb npm package, but the truth is, I still usually prefer to make my own everything until I run into trouble. I mean, isn’t that what this whole series is about? I clearly don’t learn!
Axios
What may not be evident, is how Axios and the browser-native Fetch differ. Of course Axios is essentially a library on top of XMLHttpRequest or the Fetch API. Axios simplifies the request chain a little bit, puts a slightly friendlier face on the request and response objects, and handles HTTP errors a lot cleaner than Fetch. Also, it has a bunch of great features like a cancellation token system, which is a little tough to use but better than my own absent one.
(Tweet back on Twitter)
(Discuss with Disqus!)
posted under category: General on October 18, 2021 by Nathan
A blog series in which I confess to accidentally having written my own poor version of a solved problem
React was frustrating.
I had the pleasure of getting to rewrite our customer survey at work. It’s like “how do you like your airplane” kinds of questions. This was 2016 and I was looking forward to a 6-month task that required us to beef up the security and improve the looks for a helpful little program. Of course I chose to rewrite the whole thing, which had me shopping for front-end frameworks. Everyone was talking about React at the time, so I decided to give it a shot. What went wrong?
React basically has two modes: 1, you build the whole application in React, which requires live sacrifices made to the great and powerful NPM, forcing you to buy into the entire lifecycle of new JS development and everything that comes with it, or 2, you manually construct your html with the React.createElement() function, which is a fate worse than going back to the pre-CSS days of the internet. There’s actually a third way I found out. For the small price of a 22mb JavaScript bundle download, you could load the entire Babel transpiler into your browser! Uhhh, no thank you!
That was the state of things in 2016. I know it’s gotten a a little better since then. Don’t @ me.
So React left me out in the cold. I played with it for some time and just decided to give up, however I couldn’t give up the notion of component-based development and JavaScript-powered UI templating, plus immutable-state-driven UI. It was the right choice for this interactive project, I just didn’t like how the only framework I’d heard about solved this problem.
(I have a lot of other gripes with React, maybe someday I’ll finish this rant)
Apparently that’s as far as my research got me, so I whined and moaned about it for days like the grown man I am. “Why isn’t there a framework that does what I need?” Eventually I decided to move on and just make my own with a little bit of what I knew.
Really, I built some simple bridges between two basic technologies: jQuery and Mustache, then a few convenience functions to make it all come together.
jQuery is, of course, the simplest little library for finding and manipulating elements in the DOM. I knew it like the back of my hand so I knew I could fit it in, under budget.
Mustache.js is the less popular feature of this pair. It’s the smallest client-side templating engine I could find that could still get the job done. Mustache is the little cousin of the broader Handlebars library. It does some basic templating loops and variable outputs with curly brace {{ mustache }} syntax for the magic.
Mustache doesn’t have an easy way to attach itself to the DOM, or to produce highly interactive components, nor can it load components across external files. That’s where jQuery shines. jQuery can easily mount Mustache components and keep them interactive for subsequent user events. An HTTP call with jQuery would be all that’s needed to bring in and cache my component files.
I also thought about the concept of state-driven UI, and I was enamored with the idea of state changes that drive what’s shown. It’s a natural fit for getting the data right and being able to visible debug it. React uses setState() to change things - something like that would be easy enough to implement. Luckily I didn’t feel the need to write any major reactive data systems. I emulated my understanding of React’s state management through a finite state machine that controlled state changes. These state events are like nextQuestion and completeSurvey.
Did I succeed in creating a great JavaScript framework? That’s laughable. You know the answer. I did not.
But did I at least come up with something that worked better than React for my situation? You better believe it.
What did I learn?
Remember kids, you can build world-class enterprise apps with the tools you already have on hand. It helps to read a few books beforehand; I think I had just finished a couple of my favorite short reads - Javascript: The Good Parts and The Facts and Fallacies of Software Engineering which put me in the mood to build something great.
Of course looking back now, I realize Vue.js was already 2 years old. I suppose I should have done a little more research!
Vue.js
Fast forward 2 years. I’m on another project dealing with production factory analytics. By now there was a lot of internet dev chatter about the big-3 frameworks - React, Angular, and Vue. I did my research and picked Vue at 3pm on a Thursday. My buddy Joseph and I, pair programming, included Vue.js onto the page, mounted it to a DOM element, and instantly I was able to loop and output properties. It was way easier than React, and much more powerful than Mustache. I was instantly hooked! I rolled out the feature change before I went home. The very next morning we got comments on how quickly that page seemed to be running.
That was the day I began to realize that Vue was the framework I had wanted all along, and attempted to build. Sure, I built a cheap, duct-tape-and-shoestring version, but Vue was what I was dreaming about.
As I studied the Vue.js framework a little more over the next few months, I quickly began to realize that Vue was so, so much more. Vue’s reactive data system is so far beyond the cheap state management solution I had, that I can only look back and laugh now. That simple include-the-script idea was there by design to lure folks like me into the NPM world. Tricky.
(Tweet back on Twitter)
(Discuss with Disqus!)
posted under category: General on October 16, 2021 by Nathan
A blog series in which I confess to accidentally having written my own poor version of a solved problem
I joined a new project at work. OK, joined is a polite word. A product was thrust into my lap. It has great documentation and lots of clean code written --maybe generated? Nevertheless the generator was missing and so were all the previous developers. One thing it had in spades was a strong MVC N-Tier Architecture. This made it really easy to find things, change things, and understand how the system worked.
By the way - if you do this for your application, you’re doing this for the next dev that maintains your application - and we thank you!
As I maintained this application for a while, I began to notice similarities in parts of the application that really were redundant. Specifically the data access layer. It was split between data access objects (DAOs) and data gateways (DGs). While the DGs had a lot of odds and ends that would return various recordsets, the DAOs had the same system over and over. CRUD. Load a single record and populate a single object. Read a single record and perform an insert or update. Delete a single record from the database.
The only things different were the names of tables and the names of the columns. There were a couple one-off tables without a single PKID column, but those weren’t the meat of the system.
I began to literally sketch out some potential solutions. The end result looked a little bit like this:
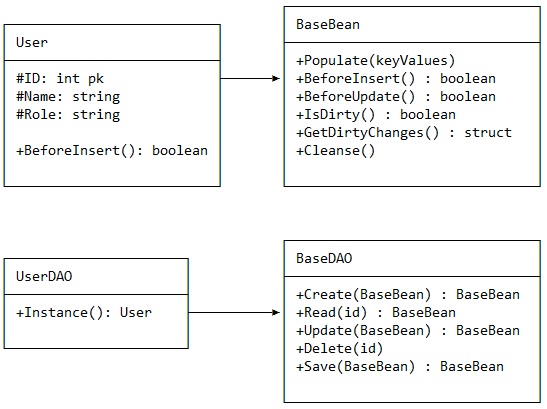
I began playing with constructing the SQL statements for each table based on component metadata. Properties in my components would probably need some custom metadata, but that both helps get this job done, and self-document the system a little better. Did I mention I was using ColdFusion for this? It makes things so simple. Watch.
The user class starts off looking like this
component {
property name="id";
property name="name";
property name="role";
}
Thanks to ColdFusion’s custom metadata system, I can throw anything I want on there, then pull it out when I’m building my DAO queries.
component table="user" {
property name="id" pk="true" required="true" sequence="seq_user_id;
property name="name" type="string" required="true";
property name="role" type="string";
property name="someDynamicProperty" persist="false";
}
So on one end, I used this to build my CRUD queries, then on the other side, I used the metadata to map the recordsets back into the models. It was actually pretty simple, once it all worked.
I tried it out for a few new tables as part of a new feature. That’s how you add your innovations and entertainment, by the way – you make the fun stuff a “critical” part of the less-fun stuff. Once that worked, I spread it across the rest of the system. In one day I reduced the codebase by 3,000 lines!
I took it a little further by auto-generating some basic list functions, like the neat little listByCriteria where you send in an object from the table with the properties you want to find.
var criteria = new User();
criteria.setRole("Admin");
var admins = dgo.listByCriteria(criteria);
What did I learn?
It’s a lot of work up front to generate your own queries, but a lot less work in the long run when you know you’re getting the most optimized experience you can. Sure the ORM here was simplistic, but so were the needs of the application.
When you make something that’s like a framework, but it stays as part of a single system, it tends to integrate tighter than you expect. This ORM became an integral part of the application it grew from. The downsides with that are that it would have been very difficult to replace it with a publicly available ORM, and it became harder and harder to reuse it in another system. In this ORM’s case, it never grew out of this application.
Of course, now that other ORMs exist, I don’t think that I would do this again. However… I have another one coming up that would prove me wrong. Stay tuned.
(Tweet back on Twitter)
(Discuss with Disqus!)
posted under category: General on October 14, 2021 by Nathan
A blog series in which I confess to accidentally having written my own poor version of a solved problem or popular framework
It was 2009, and I thought to myself “jQuery is just so verbose.” I mean look at this code I have to write in order to download an HTML fragment from the server and inject it into an area on my HTML page.
$("#target-area").load("/api/users/list");
OK, Ok, ok. It’s not that bad. But imagine you did this with Prototype.js, the dominant framework before jQuery existed.
new Ajax.Request("/api/users/list", {
onSuccess: function(response) {
$("target-area").update(response.responseXML);
},
});
Or imagine you started the project without a JavaScript framework
function reqListener () {
var el = document.getElementById("taget-area");
el.innerHTML = this.responseText;
}
var oReq = new XMLHttpRequest();
oReq.addEventListener("load", reqListener);
oReq.open("GET", "/api/users/list");
oReq.send();
I was on a project for a short time that had hundreds of screens with code like this – all customized for each and every page, all repeated, with so much boilerplate bloat that I questioned the reason for software altogether. If we add input fields into that code along with form submissions, validation, error messages, and so on, you can imagine how quickly we had JavaScript files that were tens of thousands of lines long. Then came the memory leaks, name conflicts, and maintenance.
Yes we could have done better, but I was just a loan-in, and I wanted to see what kinds of things we were building elsewhere in the company. The point is, this application made me afraid of what we could create if we didn’t start thinking about systems to handle bloat before we had problems with it.
I had an idea. What if we could implicitly load content based on some basic HTML, and use jQuery to sniff out what needs to be loaded. Just follow me down this trail for a minute.
What’s an ideal amount of JavaScript to write? None! Stupid question, I know! I figured that this is the perfect job for a data attribute. I only need to tell the content where to go, like so:
<a href="/api/users/list" data-target="#main">Users</a>
The first version of this HTML-powered, server-side rendered app looked something like this:
$(function(){
$(document).on("a[data-target]").click(function(e){
e.preventDefault();
$($(this).data("target")).load($(this).prop("href"));
});
});
It ballooned up from there, into a few hundred lines of code that handled global and inline loading spinners, delete confirmations, forms, caching, and errors.
Ahh - but you must be thinking: if the server is generating those HTML fragments, what happens when I open the link in a new tab? Well, jQuery’s AJAX api sends a HTTP header to let us know if we are in an AJAX request. With that header in place, the server sends an HTML fragment. When that header isn’t there, the back-end framework will wrap the fragment into the layout and send a full page.
It’s only a matter of the fragment being rendered with the full layout, or without.
Does that really work? Yes! It turns out it works really well. This web app was 100% functional without JavaScript. Why? Convenience! Also, users found they could open links in new tabs without a problem.
In today’s terminology, I think we would call this a hybrid SPA/SSR. Yes the discount, dollar-store version, but still, it fits the bill. Really, it was a pretty successful project.
What did I learn?
When I attempted to adapt it to another application, I learned that I either needed to cut this ‘framework’ up into smaller, individual parts that could be used independently, or bundle it all together as some kind of super-framework. Just taking parts of it was not a portable solution.
That doesn’t mean it was a waste. Not at all. This framework as its own glue for what it is, is a really cool solution that makes one application pretty easy to read and work on.
(Tweet back on Twitter)
(Discuss with Disqus!)
posted under category: General on October 13, 2021 by Nathan
A blog series in which I confess to accidentally having written my own poor version of a solved problem or popular framework
It was 1999. I worked at a small agency in Alaska, and I just learned to program in ColdFusion. I drank Mountain Dew and exclusively ate from Taco Bell. A guy at work, probably 15 years my senior and trying to escape code, told me about how to arrange an application, recommending that I make a “fusebox” - a big switch statement that would control what gets called and shown. I started piecing it together.
The project was an online storefront for a local music producer. This was my first real programming project at work, if you don’t count small JavaScript image replacement and form validation scripts, way before CSS and HTML would do these things for you! I frequently forget that I’m old until I say things like this.
So I set up a switch statement with the expression being url.action (the action property in the query string). The switch cases are includes to individual view files, or database calls with a redirect back to another action.
Really this isn’t too different from modern-day frameworks - a router, views, and room for back-end activities.
What did I learn?
It was nice to have a central place to apply security and global request filters. With all the requests coming in through this one file, it was the central hub of the application. That also opened it up to trouble. One coding mistake on the switch meant that the whole application was broken. I made a lot of coding mistakes back then, so things broke frequently.
I used an include for the HTML header and footer, so those just got included right on the switch page. Easy way to make a layout, even if it’s rather lame by today’s standards.
I initially had all the database communication right there in the switch. That really doesn’t scale since that flux capacitor there is now doing literally everything for the whole application. Pretty yucky but I didn’t know better.
Also, this being one of my first professional projects ever, I quickly realized the need for better organization by filename taxonomy.
Fusebox
The first version of Fusebox was merely a word, a convention of organization, which was really not much different than what I had built as a teenager. I’m sure it was at least a little more formal than that, but the internet was young and we didn’t exactly google for information – you had to know someone.
The second version of Fusebox had some official files - some amount of hard matter for the framework. Fusebox 3 actually set you up with structure and files and sub-folders of switches - a real framework finally.
Fuesbox eventually became the gold standard for frameworks in the world of ColdFusion. It was a short-lived title, in those years when XML was cool, before object-oriented features were added.
Have you built your own framework like me?
(Discuss with Disqus!)
posted under category: IDEs and tools on February 13, 2021 by Nathan
I mentioned how I’m teaching a high school coding class at our home school co-op. At the beginning of the 2020/2021 school year, I specified that students need a Windows laptop, or a Mac if there was no other option. I don’t like to support Apple devices. I specified that no Chromebooks would be allowed in the classroom. It was the right choice last August, but this next school year, I’m going to let Chromebooks in.
Every week I write up a new presentation in Google Slides, and present it to the class on my Chromebook. Between Google Docs for the slides and GitHub for the files, I have access to everything I need across all of my devices. But what about coding on the Chromebook? Aren’t Chromebooks underpowered laptops with nothing but a browser? How’s the coding experience, you ask? I’m so glad you did!
First, you should know that every Chrome OS device is essentially three things:
- A Google Chrome web browser device - the classic foundation and namesake it’s had since 2011
- An Android tablet with full access to the Google Play store and most Android apps and games, in fairly performant windowed environment, since 2016
- A Linux laptop with a Debian terminal that grants full access to apt-get anything you want, since 2018
There are some really great in-browser IDEs, but I like to keep things local and offline, cutting my choices down significantly. There aren’t any great Android-based IDEs that I’ve seen. But wouldn’t you just want to use everyone’s favorite coding tool? That’s right, I want VSCode on my Chromebook. And guess what? It’s become really easy to do this!
The steps have become essentially the same as they would be on any other operating system. Visit the VSCode website, click the giant download button, then double-click the installer. This was much harder only a few months ago! I was taken back when I had the chance to install it on a new device recently. It’s seamless. I also double-checked that it added VSCode as a known repository for the integrated package manager so that upgrading can be done with sudo apt-get update && sudo apt-get upgrade -y. Or of course you can go download the new version and run the installer again. That’s not quite as seamless as it is on Windows, but it’s not bad at all.
At the start of the 2020 schoolyear, I had an outdated Acer R11 Chromebook with a flimsy Celeron CPU. It performed fine, but the lower resolution 11 inch screen was pretty small for the task at hand, and starting VSCode was a commitment.
This year I invested my incredible teaching profits (that’s a joke!) when I found that Lenovo’s Chromebook line finally includes the incredibly affordable and powerful 10th gen i3 model with 8GB of memory. It’s a steal at $440. I’m not trying to advertise, but I do have an affiliate link to look at it on Amazon because it brings me some happiness and maybe you’d like to check it out. Something amazing about this device is that it launches VSCode in about 1 second - there’s no delay. It’s faster than my i7 work laptop. It has plenty of power for this job!
So my Chromebook has VSCode. What next?
Extensions! They all work. Everything I throw at it works perfectly. I’m not missing anything in this department.
Debugging! Works perfectly. I’ve only tried debugging JavaScript, web pages, and C# code, maybe Python last year, and they are every bit as capable as anywhere else.
Coding! Duh. It definitely works.
Anything wrong?
Only one thing doesn’t work for me. It’s the standard Chromebook keyboard. Not even the physical keys, this Lenovo has good feel for such a quiet sound. My gripes are about the keyboard on Chrome OS devices, namely these complaints -
- The lack of a 6-key insert-delete, home-end, pageup-pagedown block is annoying enough. I miss that on every notebook keyboard though. The problem is that these keys literally don’t exist. On a Windows laptop, I can at least find these keys. They’re often hidden behind a function control key, but they are there. There’s no chance to find them on Chrome hardware.
- No delete key. There is a way to delete -
alt+backspace will delete in front of the cursor, while the standard backspace key only deletes what is behind the cursor. If you ever want to delete a file, you are forced to make the two-finger-salute.
- Alt + Click is a right-click in Chrome OS, instead of the standard multi-cursor selection combo in VSCode. I suppose this is configurable so I can change it to the Ctrl key, but it’s very annoying.
Of course all of that can be ignored if you plug in an external keyboard. I’m not carrying a keyboard around in my bag, or over to the couch, so I just have to live with the pain.
Wrap-up
Coding on Chrome OS is great with VSCode, and it’s a very workable solution. Get a powerful processor, no Celerons or Pentium chips, and get plenty of memory. If you’re settling down for a long coding session. bring an external keyboard and mouse just like you would want with any laptop. Now that VSCode works flawlessly, the gates are open wide!
(Discuss with Disqus!)
posted under category: Life Events on February 9, 2021 by Nathan
I have a handful of small things that I don’t want to write up in long-form, so here are a bunch of them.
COVID stay-at-home orders have been fine
Ups and downs, for sure. Work had previously taken a hard stance against working virtually. They did a hard 180° last March, and none of us have visited the office once since then. I hope somebody ate that Cliff Bar on my desk. I would like to bring my chair home, however. I have an AmazonBasics chair at home, which was fine for the amount of time I needed it, up until last March. Now I’m wishing I spent more money on it.
Through the Spring, we scheduled theme nights at home. Hawaiian night. Video game night. Science night. We probably had a dozen of them. All the kids got to pick at least one, and we’d use whatever decorations we had to make it a party. I highly recommend this activity.
South Carolina has actually been pretty chill about it. We’re happy enough to mask up, even if it’s just for show, but if that’s what keeps my favorite restaurants open, then I’ll wear 2 masks if I have to. We’ve had a bunch of friends with COVID, but very few serious cases, and no deaths in our circles of friends. My airplane company is struggling though. We’ve had lots of layoffs - some of it for the better but most of it just for the sadder.
Homeschooling has actually been successful
My oldest child graduated high school, a year early, and even started college with a scholarship! As a homeschooling parent, this is a huge win for us. We decided to homeschool her when she started reading chapter books going into kindergarten. I guess firstborns are always early. We’ve been keeping it up, and now really identify ourselves as a homeschooling family. It’s a weird thing, but honestly it just keeps working out. Especially in light of the trainwreck that was 2020.
Both of my teenagers got jobs where they make pretty good money and are liked by their peers. Again, a homeschooling win. They’re responsible, and they make me proud. That makes a dad’s heart warm!
I love Vue.js
I don’t think I’ve talked about it on here. I fell in love with Vue when I first saw it. Actually I created something a lot like it when I first stumbled over my dislike for React, but before Vue was popular enough for me to hear about it. I always say that you need a framework only when you are on the verge of creating it yourself. That’s where you firmly discover your need. I settled for a bastardization of jQuery and Mustache - that’s how much I disliked React.
I understand React, and really I cut my teeth on it as my first all-encompassing JS framework (“but it’s a library” - not when you use Redux, React Router, and the millions of little packages you need to make a React app work), but I just genuinely hated… well… everything about it. It was partly the naming schemes for events (“componentDidUpdate”, “componentWillReceiveProps” - these are terrible!), it was partly that there was essentially no way to progressively implement it into an existing website, partly because you pretty much can’t use it without Babel and everything that entails, partly because the documentation was barely workable, partly because Facebook, partly because they keep changing major things, partly because Hooks aren’t actually a great software development solution, partly because they add feature that never become official (suspense anyone?), largely because everything in React-land is so verbose and involves a lot of typing, partly because the ecosystem is so fragmented and there are actually too many bad choices you can make with libraries and application design that will create terrible programs, partly because JSX is strange and feels very non-standard, and partly, finally, because I really just have my preferences and React isn’t what I prefer. I dislike it. To be a little more fair, the docs have improved, the lifecycle events have evolved a bit, and the code required to make it go has been getting better thanks to functions over classes and the Redux Toolkit over plain Redux.
I really do “get” React - function call in, HTML out. It’s just that Vue is better, faster, more efficient, more obvious and predictable, easier to work with, the tooling is better, the first-party libraries are better, and the happy-path to success is very easy to find. If you’ve ever worked with React and wondered if there’s anything better, there is.
So Vue is my preferred front-end. I like it in the browser as an included script like jQuery. I like it in a manual Webpack that does just enough. I like it wrapped up and intertwined with my back-end. I like it in a full standalone CLI. I love that it grows with whatever project I have for it. Vue is really great.
My preferred back-end
Years ago I swore by ColdFusion. I mean, it was the best thing going in 1998. Way better than… what did we even have back then? ASP. PHP. JSP. Nah bro. Allaire Macromedia Adobe ColdFusion was definitely the easy path. I mentioned a while ago how my lil’ company has been moving us off of that - and for good reason. We can get the same job done in other platforms. They’re different. There’s something about googleable stackoverflow questions that make a lot of platforms work for you. I set out to find out what was up with .NET, and found my way into .NET Core. I’ve always been a fan, as C# was a pet language to me.
A couple years ago, a couple of us met with Damian and some of the .NET team as representatives of the hundreds of ColdFusion programmers at my company. They were really nice, listened to our feedback, showed us some interesting things coming up, and gave us help getting started on converting a 100 year old company to Microsoft’s software stack. It was nice. So I’ve officially jumped ship and have been coding up all of my APIs in .NET Core running on our private cloud over the past few years. It’s been very successful.
Something I didn’t expect though, that I should have seen coming, is that the .NET Core stack has really just become a thin middle layer between a database and a complex UI. Sure every app is different, but we’ve moved a lot of complexity into JavaScript.
I have a little advice for ColdFusion coders. Immerse yourselves in OOP and FP - there are reasons programmers talk about this all the time. In the CF world, you can get away with doing pretty much anything, but in C# your hands are bound - in a good way, but a challenging way. Learning object-oriented programming and functional programming today will pay off both today and tomorrow. Your CFML will be better, and your non-CFML will be better and you’ll be able to switch more easily.
(Discuss with Disqus!)
